Recenzia na DOXXbet kasíno
- O spoločnosti
- Ukážka lobby
- Registrácia v DOXXbet
- Platobné metódy
- Vstupný bonus 10 000 € + 250 spinov
- Hry mesiaca a 50 € BONUS
- Mesačný VIP Bonus až 300 €
- Mobilná aplikácia
- Zákaznícka podpora
O spoločnosti
Stávkovanie a zábava so skúseným hráčom na trhu. Stávková spoločnosť DOXXbet je na medzinárodnom trhu už od roku 1990. V hernom a stávkovom priemysle stihli nazbierať množstvo cenných skúseností, vďaka ktorým si teraz s Doxxbet užijete kopec zábavy. Od roku 2013 sú aj na Slovensku plne licencovaná stávková kancelária regulovaná zákonmi SR, čo v praxi znamená úplne bezpečné tipovanie.
16. januára 2020 spustila spoločnosť DOXXbet na svojom webe a mobilnej aplikácii nový produkt, a to online kasíno pre všetkých slovenských hráčov. Toto kasíno má názov DOXXbet Kasíno. Zabávať sa v ňom môžete vďaka luxusnému vstupnému bonusu, širokej ponuke kasínových hier, pravidelným turnajom či promoakciám pre nových ale aj existujúcich hráčov.
Ukážka lobby
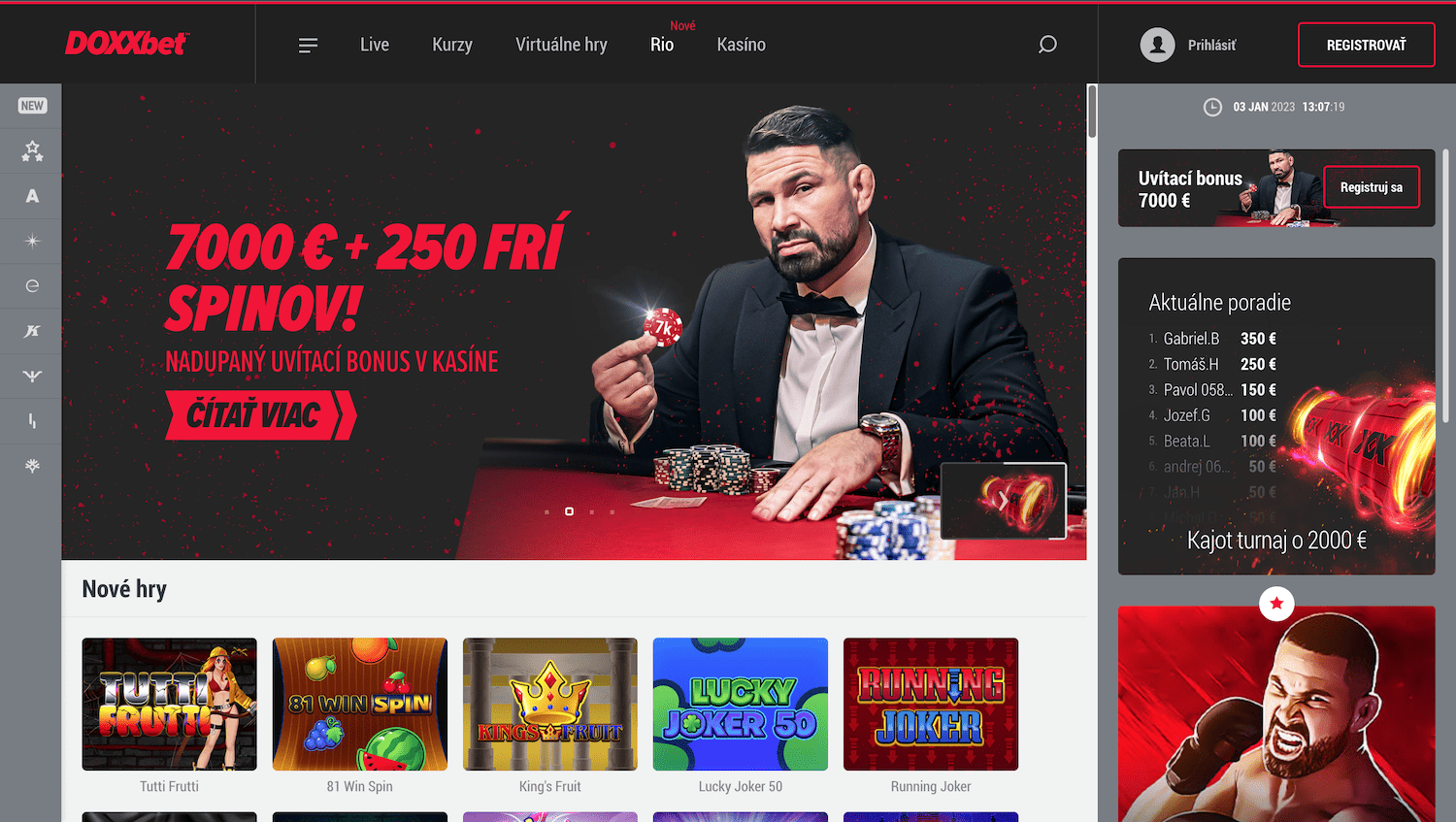
Registrácia v DOXXbet
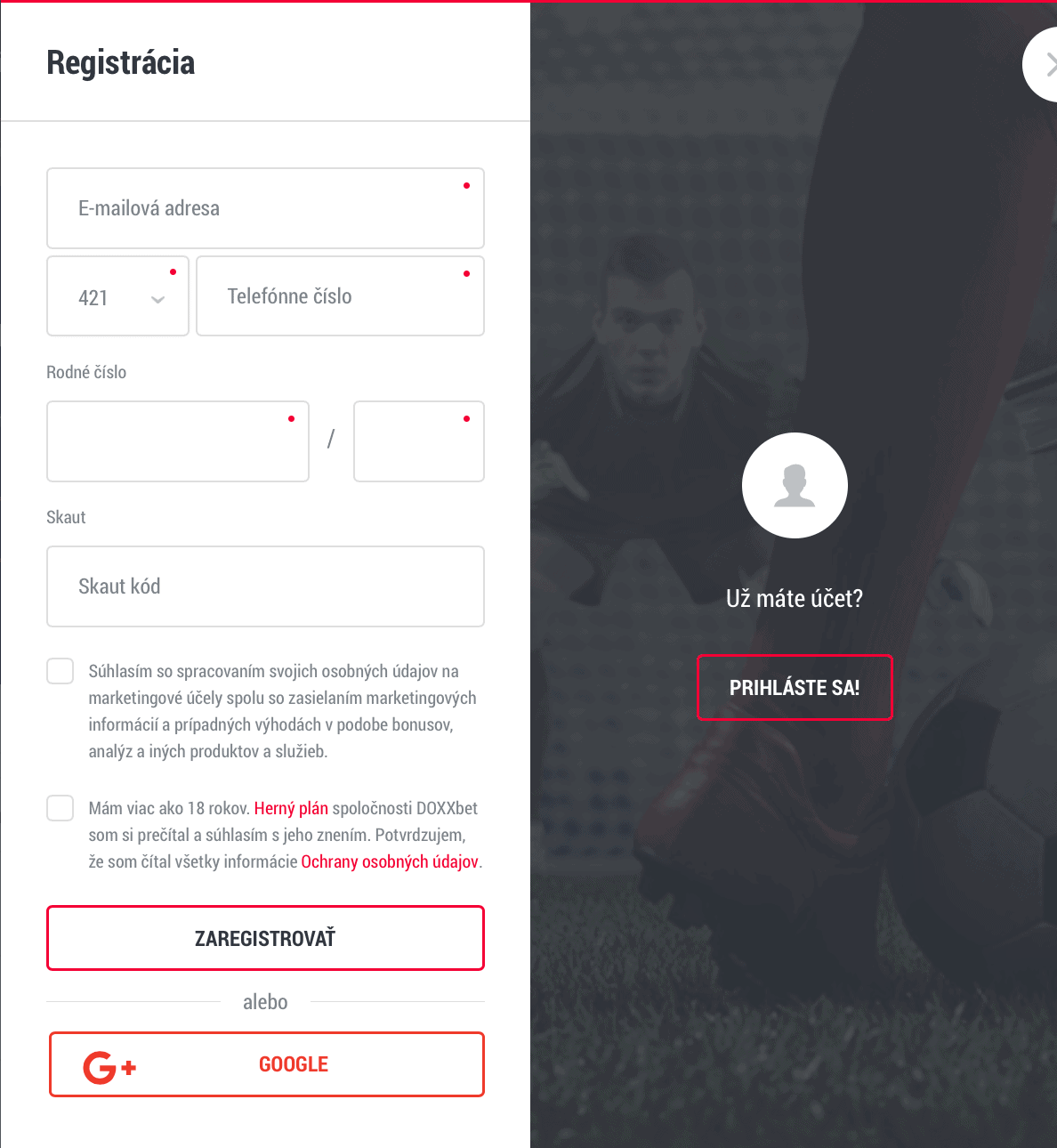
Ak si v stávkovej kancelárii DOXXbet chcete založiť účet, prejdite na registračnú stránku. V registračnom formulári dôkladne zadajte všetky požadované údaje. Všetky vaše údaje musia byť pravdivé a správne. V registračnom formulári je políčko „Promo kód“, ktoré však pre získanie vstupného bonusu nemusíte vypĺňať. Ide len o akýsi doplnok, ak vlastníte dodatočný promo kód. Po dokončení registrácie vložte peniaze na svoj nový stávkový účet a začnite tipovať.
Platobné metódy
Vklady
DOXXbet kasíno ponúka širokú paletu vkladových metód pre svojich hráčov. Medzi najzákladnejšie a najrozšírenejšie patria platba cez platobné karty VISA a MasterCard, ktoré majú limit 5 € – 2000 €. Nastaviť si môžete aj opakovanú platbu kartou, vďaka čomu si zapamätáte svoju kartu v účte a pri ďalšom vklade už nemusíte vypĺňať svoje platobné údaje. Dostupná je aj platba cez Apple Pay pre iOS užívateľov.
Hráčov v DOXXbet najviac potešia asi okamžité vklady cez internetbanking všetkých veľkých bánk na Slovensku. Peniaze máte ihneď na účte a za prevody neplatíte. Na vklad pritom využívate rozhranie banky, kde sa prihlásite, alebo svoju mobilnú appku internet banking. Maximálny limit je jednotný pre všetky banky, a to 2000 €. Ak chcete vložiť vyššiu čiastku, odporúčame klasický bankový prevod, kde je maximálny limit nastavený až na 20 000 €.
Dostupná je aj elektronická peňaženka Skrill (Moneybookers), pričom minimálny vklad je 10 €. Vklad je ale spoplatnený poplatkom vo výške 5 % z vkladanej sumy. Rovnako môžete využiť aj predplatnú kartu Paysafecard, ktorú si môžete zakúpiť v supermarketoch alebo novinových stánkoch.
Ďalej je tu možnosť vkladu prostredníctvom kreditného lístku zo sportboxu (čo sú terminály v rôznych prevádzkach) alebo vklad je možné uskutočniť aj cez VIAMO, ktoré je dostupné pre klientov VÚB a Tatra banky.
Výbery
Jediná možnosť výberu peňazí z vášho hráčskeho účtu v DOXXbet je využitie bankového prevodu cez 24pay. Tento výber je pritom jednoduchý a rýchly – peniaze budete mať na svojom bankovom účte už do 24 hodín. Nie je pritom spoplatnený, a tak za výber nič neplatíte. Limity sú pritom nastavené od 10 € do 10 000 €.

DOXXbet casino Vstupný bonus až 10 000 € + 250 spinov
DOXXbet kasíno ponúka všetkým novo-registrovaným hráčom a hráčom športového tipovania Uvítací bonus vo výške 10 €, 50 €, 100 €, 500 €, 1 000 €, 5 000 €, 7 000 € alebo až 10 000 €. Ak ešte nie ste registrovaný, stačí si otvoriť účet v DOXXbet Kasíne. Po prihlásení vo vašom kasíno profile nájdete v sekcii „Bonusy a Promokódy“ všetky Uvítacie bonusy, z ktorých si môžete jeden aktivovať.![]()
A to nie je všetko! DOXXbet Kasíno má pre vás extra 250 točení zdarma rozdelených do 4 skupín:
50 spinov ZDARMA
Pre tieto točenia zdarma si stačí overiť hráčsky účet. Následne môžete využiť 50 točení zdarma na hrách Berry Berry Bonanza, Royal Respin Deluxe alebo Gem Heat a počkať si na svoje šťastie. Výhry vám budú pripísané priamo do reálnych peňazí po každom výhernom točení.
50 spinov ZDARMA
Pre získanie ďalších 50 točení zdarma treba pretočiť v online kasíne DOXXbet na ľubovoľných hrách kumulatívne 100 €. Následne sa vám ihneď aktivujú točenia zdarma. Potom stačí už len spustiť jednu z hier Berry Berry Bonanza, Royal Respin Deluxe alebo Gem Heat a využiť točenia zdarma. Výhry vám rovnako budú pripísané priamo do reálnych peňazí po každom výhernom točení.
50 spinov ZDARMA
Pre získanie 50 točení zdarma tretíkrát treba pretočiť v DOXXbet online kasíne na ľubovoľných hrách kumulatívne 250 €. Následne sa vám ihneď aktivujú točenia zdarma. Potom stačí už len spustiť jednu z hier Berry Berry Bonanza, Royal Respin Deluxe alebo Gem Heat a využiť točenia zdarma. Výhry vám rovnako budú pripísané priamo do reálnych peňazí po každom výhernom točení.
100 spinov ZDARMA v hre Berry Berry Bonanza
Pre získanie posledných točení zdarma v rámci Uvítacieho bonusu je potrebné pretočiť na ľubovoľných hrách kumulatívne 500 €. Následne sa vám aktivujú točenia zdarma podobne ako pri predošlých skupinách. Potom stačí už len spustiť hru Berry berry Bonanza a zabaviť sa pri jednej z najobľúbenejších hier na slovenskom trhu. Výhry vám budú rovnako pripísané priamo do reálnych peňazí po každom výhernom točení.
Ako funguje vkladový Uvítací bonus?
Po aktivácii jedného z ponúkaných bonusov musíte v priebehu nasledujúcich 30 dní vsadiť 10 až 40-násobok výšky daného bonusu v reálnych peniazoch. Následne sa vám bonus pripíše na konte do reálnych peňazí.
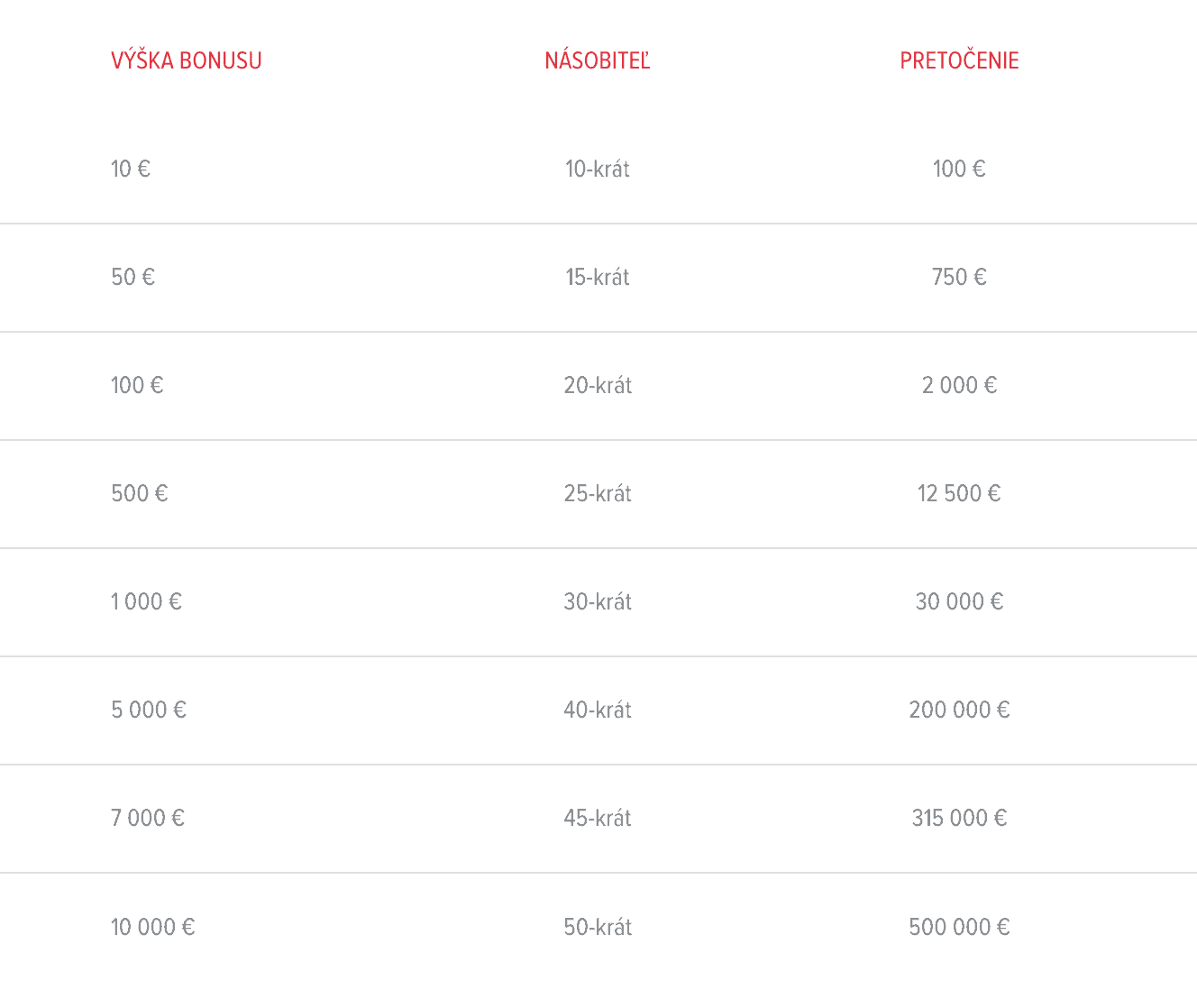
Príklad: Ak si aktivujete bonus 10 €, musíte pretočiť za reálne peniaze jeho 10-násobok, teda 100 €. Následne sa vám bonus prevedie do reálnych peňazí.
Zaregistrujte sa a získajte vstupný bonus v DOXXbet kasíne.
Hry mesiaca a 50€ BONUS
Skvelá DOXXbet kasíno akcia, ktorá vám pripraví každý mesiac tú správnu vzrušujúcu zmenu. DOXXbet vás každý mesiac prekvapí novými hrami alebo vyberú z TOP aktuálnych hier tie, ktoré sa stanú aj vašimi Hrami mesiaca. Informovať vás o nich budeme aj na našom webe. Následne už len stačí aktivovať si po prihlásení sa do svojho konta bonus „Hry Mesiaca“, ktorý nájdete v sekcii „Bonusy a Promokódy“.
Bonus však môže byť použitý na stávkovanie až po splnení podmienok. Počas 20 dní stavte 1 500 € na vybraných hrách daného mesiaca a bonus 50 € sa automaticky prevedie na váš hráčsky účet ako vyberateľný bonus.
DOXXbet Reload Bonus 20 €
Budete aktívnym a pravidelným hráčom v DOXXbete? Toto kasíno vás za to odmení každý mesiac bonusom 20 €, ktoré nazvalo ako Reload bonus. Ak si tento bonus aktivujete každý mesiac, môžete získať až 240 € ročne, a to nie je vôbec suma na zahodenie.
DOXXbet Bonus 20 € získate, ak počas mesiaca stavíte v kasínových hrách aspoň 1000 €. To je jediná podmienka. Do pretočenej sumy sa vám pritom rátajú ako stávky v online hracích automatoch, tak aj v stolových hrách ako ruleta či blackjack. Podmienku pretočenia pritom musíte splniť počas 20 dní od momentu aktivovania bonusu.
DÔLEŽITÉ! Ak chcete získať Reload bonus 20 €, musíte si tento bonus aktivovať priamo vo svojom kasíno profile v sekcii „Bonusy a Promokódy“.

Mesačný VIP Bonus pre aktívnych hráčov až 300 €
DOXXbet kasíno myslí aj na svojich VIP hráčov, ktorí sa neboja hrať o vysoké sumy. Ide o VIP program odmeňovania, ktorý funguje na jednoduchom princípe – čím viac počas mesiaca stavíte, tým vyššiu odmenu získate.
Hrajte svoje obľúbené kasíno hry či hracie automaty a DOXXbet vás za to rád odmení. Pretočte v kalendárnom mesiaci v hrách minimálne 2 500 € a ďalší mesiac získate hrateľný finančný bonus bez skrytých podmienok pre úspešný štart do nového mesiaca. Obrat 2 500 eur vám prinesie bonus 5 € na váš účet, no tu to celé len začína. Obrat je vystupňovaný do úrovní podľa výšky hodnoty vašich stávok, a to až do hodnoty 100-tisíc eur. Ak vložíte do automatov a casino hier v DOXXbete túto a vyššiu sumu za mesiac, hneď začiatkom toho nového získate maximálny bonus 300 € ako VIP hráč.

Na získanie tohto bonusu sa nemusíte nikde registrovať ani prihlasovať. Do celkovej pretočenej sumy sa vám automaticky zarátavajú všetky vaše stávky v kasíne DOXXbet.
DOXXbet mobilná aplikácia
DOXXbet mobilná aplikácia je vaša cesta k ešte väčšej a rýchlejšej zábave – vo vašom mobile, ktorý máte neustále vo svojom vrecku. A s ním aj celé DOXXbet kasíno. Hrajte svoje obľúbené automaty, zapájajte sa do turnajov a hrajte o vysoké bonusy jednoducho zo svojho mobilu bez zbytočného prihlasovania.
Ako Android, tak aj iOS (Apple) používatelia si do svojho zariadenia môžu stiahnuť mobilnú aplikáciu kasína DOXXbet. Jediným rozdielom je to, že Apple používatelia majú stávkové kurzové stávkovanie a online kasíno rozdelené do dvoch samostatných appiek, zatiaľ čo v Android zariadeniach to majú používatelia spojené. Rovnako sa ale môžete rozhodnúť, že budete hrať v mobilnej verzii webu kasína, pričom ani vtedy vás to neuberie o zážitok. Mobilný web je rýchly a dokonale responzívny.

Skvelou správou a dôvodom, prečo sa rozhodnúť pre aplikáciu, je ale to, že akonáhle si aplikáciu stiahnete a prihlásite sa do nej, získate 100 vernostných bodov do vernostného programu. Ide o jedinečný program, kde máte šancu získať exkluzívne ceny. Špičková elektronika, štýlové vecné ceny, merch Attila Végh alebo voľné stávky. To všetko môžeš získať jedine za vernostné body.
Zákaznícka podpora
Ak máte nejaký problém s účtom, registráciou alebo roztáčaním online automatov, vždy príde vhod skúsená zákaznícka podpora, ktorú DOXX bet ponúka. E-mail, telefón či kontaktný formulár. To všetko máte k dispozícii pre vašu maximálnu spokojnosť a pohodlie. Na webových stánkach DOXXbet máte taktiež po ruke aj Live chat, kde vám pomôžu zamestnanci stávkovej kancelárie.
Web: doxxbet.sk
Adresa: Kálov 356, 010 01 Žilina
Tel. číslo (podpora): +421 911 569 909
E-mail (podpora): info@doxxbet.sk
Zaregistrujte sa v DOXXbete a získajte jeden z najvyšších vstupných bonusov na Slovensku a tiež množstvo výhod a prémií pre aktívnych hráčov.
Nemáte ešte účet v DOXXbet online kasíne? Zaregistrujte sa a získajte vysoký vstupný bonus:
- Vyplňte registračný formulár TU a vytvorte si účet v DOXXbet
- Získajte 50 free spinov bez podmienok a ďalších 200 spinov po pretočení
- Zadajte pri registrácii náš SKAUT kód AFF1074 pre extra bonus 25 spinov + 3 € voľnú stávku
